03. kube-scheduler 调度队列
调度的本质可以概括为一个“取出 → 评估 → 绑定”的过程:从调度队列中取出一个待调度的 Pod → 执行调度逻辑,评估出最合适的目标节点 → 绑定到目标节点。
所以一个设计良好的调度队列可以很大程度提升调度效率。
在 kube-scheduler 中,调度队列的核心实现位于 pkg/scheduler/internal/ 目录,结构如下:
$ tree pkg/scheduler/internal/
internal
├── cache # 调度缓存,下期介绍
├── heap # 堆结构,作为调度队列的底层结构
└── queue # 调度队列其中 heap 模块提供了调度队列的基础数据结构支持,queue 模块则建立在 heap 之上,实现调度队列核心逻辑,管理所有待调度的 Pod 。
按照优先级和调度状态, queue 划分为三种不同的子队列,即 activeQ 活动队列、podBackoffQ 退避队列和 unschedulablePods 不可调度队列。
当新建一个 Pod 加入到 activeQ 队列后,它可能因为某些原因暂时无法调度,就会被移入 podBackoffQ 或 unschedulablePods 队列,调度器会定期或在外部事件触发下重新尝试调度这些 Pod。
调度队列的底层结构
调度队列的优先级排序能力并非凭空而来,而是构建在一个更基础的数据结构之上——堆(Heap)。这部分逻辑被封装在 pkg/scheduler/internal/heap 目录中。
heap.go 文件实现了一个通用的、非线程安全的堆结构,后续提到的调度队列 activeQ 和 podBackoffQ 都基于此结构创建。
堆的核心是 data 结构体,它实现了 Go 标准库 container/heap 所要求的接口:
type heapItem struct {
obj interface{} // 对象本身
index int // 对象的索引
}
type data struct {
// items 是一个 map ,用于通过对象的 key 快速查找出对象和对应的索引。
items map[string]*heapItem
// queue 是一个字符串切片,存储了对象的所有 key ,下标即对应了对象索引。
queue []string
// keyFunc 是一个函数,用于从任意对象中生成一个唯一的、确定性的 key。
// 通过函数就可以让外部调用方决定 key 的生成逻辑,而非写死。
keyFunc KeyFunc
// lessFunc 是一个比较函数,是决定堆内元素排序顺序的核心。
// 同样让外部调用方决定排序逻辑,而非写死。
lessFunc lessFunc
}
// 两个函数的定义
type KeyFunc func(obj interface{}) (string, error)
type lessFunc = func(item1, item2 interface{}) bool
var (
_ = heap.Interface(&data{}) // 实现了标准库 container/heap 的接口
)
// 堆的核心逻辑,决定谁排在前面,最终调用的是外部传递的 lessFunc 函数来比较
func (h *data) Less(i, j int) bool {
if i > len(h.queue) || j > len(h.queue) {
return false
}
itemi, ok := h.items[h.queue[i]]
if !ok {
return false
}
itemj, ok := h.items[h.queue[j]]
if !ok {
return false
}
return h.lessFunc(itemi.obj, itemj.obj)
}
// 返回堆大小
func (h *data) Len() int { return len(h.queue) }
// 交换 queue 中两个 key,并同步更新 items 中对应对象的 index(保持索引一致)
func (h *data) Swap(i, j int) {
h.queue[i], h.queue[j] = h.queue[j], h.queue[i]
item := h.items[h.queue[i]]
item.index = i
item = h.items[h.queue[j]]
item.index = j
}
type itemKeyValue struct {
key string
obj interface{}
}
// 把对象包装成 itemKeyValue 插入,存到 items 中,并更新到 queue 末尾
func (h *data) Push(kv interface{}) {
keyValue := kv.(*itemKeyValue)
n := len(h.queue)
h.items[keyValue.key] = &heapItem{keyValue.obj, n}
h.queue = append(h.queue, keyValue.key)
}
// 从 queue “末尾” 取出 key ,删除 items 里对应的对象,并返回(弹出)对应对象
func (h *data) Pop() interface{} {
key := h.queue[len(h.queue)-1]
h.queue = h.queue[0 : len(h.queue)-1]
item, ok := h.items[key]
if !ok {
// This is an error
return nil
}
delete(h.items, key)
return item.obj
}
// 只读访问堆顶元素,非接口要求实现,后续退避队列会用到
func (h *data) Peek() interface{} {
if len(h.queue) > 0 {
return h.items[h.queue[0]].obj
}
return nil
}这里有一个有趣的点:在堆的概念中,Pop() 方法应该表示堆顶元素出堆,但在 container/heap 的实现要求中,我们的 Pop() 方法却是删除并返回切片的末尾元素(索引为 len(h.queue)-1),而不是索引为 0 的堆顶元素。
这是因为我们后续调用 heap.Pop() 对堆顶元素出堆时,其内部流程是先将堆顶元素与末尾元素交换位置,然后对剩余元素执行下沉操作保持堆性质。这样,原本的堆顶元素就被移动到了切片末尾,这时调用我们实现的 Pop() 方法就可以直接移除并返回它,从而得到真正的堆顶元素。对此感兴趣的,可以移步到 https://github.com/golang/go/blob/master/src/container/heap/heap.go 查看源码实现。
这种设计巧妙地把复杂的堆维护逻辑封装在标准库内部,用户只需实现最简单的“删除末尾”操作,就能正确、高效地完成“堆顶出堆”。不得不说,Go 标准库在抽象与易用性上的拿捏,确实非常精妙。
回到该堆结构,data 是一个较为底层的实现:实现了 Go 标准库 heap.Interface 的 Len / Less / Swap / Push / Pop 方法,虽然知道怎么维护堆的有序性,以及 map+slice 的一致性。 但是它只关注「数据结构本身」,不管外部要怎么用。
因此,对外(指调度队列),又封装了一层结构 Heap ,提供更高层的 API : Add / Update / Delete / Peek / Pop / Get / List / Len …
还为其包装了指标统计功能:
type Heap struct {
// 底层 heap.Interface 实现
data *data
// 指标计数器,用来统计堆中元素的增删
metricRecorder metrics.MetricRecorder
}
// 不带指标计数器的构造函数
func New(keyFn KeyFunc, lessFn lessFunc) *Heap {
return NewWithRecorder(keyFn, lessFn, nil)
}
// 带指标计数器的构造函数
func NewWithRecorder(keyFn KeyFunc, lessFn lessFunc, metricRecorder metrics.MetricRecorder) *Heap {
return &Heap{
data: &data{
items: map[string]*heapItem{},
queue: []string{},
keyFunc: keyFn,
lessFunc: lessFn,
},
metricRecorder: metricRecorder,
}
}
// 实现一个支持幂等的 Add 方法(存在则更新,不存在则插入)
func (h *Heap) Add(obj interface{}) error {
key, err := h.data.keyFunc(obj)
if err != nil {
return cache.KeyError{Obj: obj, Err: err}
}
if _, exists := h.data.items[key]; exists {
h.data.items[key].obj = obj
heap.Fix(h.data, h.data.items[key].index)
} else {
heap.Push(h.data, &itemKeyValue{key, obj})
if h.metricRecorder != nil {
h.metricRecorder.Inc()
}
}
return nil
}
// Update 等价于 Add
func (h *Heap) Update(obj interface{}) error {
return h.Add(obj)
}
// 可以精确删除堆中某个对象,同时更新指标记录
func (h *Heap) Delete(obj interface{}) error {
key, err := h.data.keyFunc(obj)
if err != nil {
return cache.KeyError{Obj: obj, Err: err}
}
if item, ok := h.data.items[key]; ok {
heap.Remove(h.data, item.index)
if h.metricRecorder != nil {
h.metricRecorder.Dec()
}
return nil
}
return fmt.Errorf("object not found")
}
// 调用 heap.Pop 对堆顶元素出堆,同时更新指标记录
func (h *Heap) Pop() (interface{}, error) {
obj := heap.Pop(h.data)
if obj != nil {
if h.metricRecorder != nil {
h.metricRecorder.Dec()
}
return obj, nil
}
return nil, fmt.Errorf("object was removed from heap data")
}
// 只读访问堆顶元素,后续退避队列会用到
func (h *Heap) Peek() interface{} {
return h.data.Peek()
}
// ....... 不再一一列出
通过这个 Heap 堆结构,调度队列能够高效支持以下操作:
- 插入 Pod(Add/Update):时间复杂度 O(log n),在优先级队列中高效插入或更新元素。
- 删除指定 Pod(Delete):时间复杂度 O(log n),通过索引快速定位并从堆中移除。
- 取出堆顶 Pod(Pop):时间复杂度 O(log n),返回并删除当前最高优先级 Pod。
- 获取堆顶 Pod(Peek):时间复杂度 O(1),无需调整堆即可直接访问最高优先级 Pod。
- 根据 Key 查询 Pod(Get/GetByKey):时间复杂度 O(1),依赖 map 快速定位元素。
调度队列的抽象接口
在 Kubernetes 源码中,会习惯使用接口来解耦实现与定义,提升可扩展性和可测试性。对于调度队列,便定义了一个 SchedulingQueue 抽象接口来描述一个调度队列需要具备的所有能力:
type SchedulingQueue interface {
// PodNominator 也是一个接口,抽象了对“被提名 Pod”的操作和管理。本节略过不做介绍。
// 当 Pod 抢占节点上的一个或多个 Pod 时, Pod 状态的 nominatedNodeName 字段就会被设置为节点的名称。
// 不过被提名并不代表会调度成功或者一定会调度到该提名节点上。
framework.PodNominator
// Add 将一个 Pod 插入到调度队列。
Add(pod *v1.Pod) error
// Activate 用于激活一批 Pod:如果这些 Pod 当前在 unschedulablePods 或 backoffQ 中,
// 则将它们移动到 activeQ(活动队列)。
Activate(pods map[string]*v1.Pod)
// AddUnschedulableIfNotPresent 用于把一个不可调度的 Pod 重新放回调度队列(不可调度队列)。
// 参数 podSchedulingCycle 表示当前的调度周期编号。
// 主要用于:Pod 在一次调度中失败后,后续在合适时机被重新入队。
AddUnschedulableIfNotPresent(pod *framework.QueuedPodInfo, podSchedulingCycle int64) error
// SchedulingCycle 返回当前调度周期编号。
// 每次 Pop(即取出一个 Pod 开始调度)都会递增该计数器。
SchedulingCycle() int64
// Pop 移除并返回队列头部的 Pod。
// 如果队列为空,它会阻塞等待,直到有新的 Pod 被加入。
// ——这是调度器的核心入口:不断从队列中取 Pod 来进行调度。
Pop() (*framework.QueuedPodInfo, error)
// Update 更新队列中的 Pod。如果 Pod 不存在,则会当作新 Pod 插入。
Update(oldPod, newPod *v1.Pod) error
// Delete 从队列中删除指定 Pod。
Delete(pod *v1.Pod) error
// MoveAllToActiveOrBackoffQueue 将所有 Pod 从 unschedulablePods 移动到 activeQ 或 backoffQ。
// 这个方法通常在调度事件发生时调用,例如集群资源更新,需要唤醒等待中的 Pod。
MoveAllToActiveOrBackoffQueue(event framework.ClusterEvent, preCheck PreEnqueueCheck)
// AssignedPodAdded 当一个 Pod 成功绑定到节点后被调用。
// 比如当新 Pod 被调度后,可以看看是否有其他 Pending Pod 因为它的存在变得可以调度了,如果有就重新放到可调度队列。
AssignedPodAdded(pod *v1.Pod)
// AssignedPodUpdated 当一个已绑定的 Pod 被更新时调用。比如修改了资源(CPU/内存)、标签(Labels)等
// 作用同 AssignedPodAdded
AssignedPodUpdated(pod *v1.Pod)
// PendingPods 返回所有等待调度的 Pod 列表,以及一个调试信息字符串。
PendingPods() ([]*v1.Pod, string)
// Close 关闭调度队列,使得正在等待 Pop 的 goroutine 能够优雅退出。
Close()
// Run 启动调度队列的管理协程(例如 backoff 处理、定时器等后台逻辑)。
Run()
}调度队列的内部结构
kube-scheduler 的核心调度队列实现是 PriorityQueue 结构(实现了上面的 SchedulingQueue 接口),它并非只是一个简单的优先级队列,而是一个复杂的状态机。为了精细化管理不同状态的 Pod,PriorityQueue 在内部划分了三个关键的子队列:
type PriorityQueue struct {
// 条件变量,用于在队列为空时阻塞 Pop(),并在有新项加入时唤醒它。
cond sync.Cond
// activeQ 是一个堆结构,调度器会主动从此队列中查找要调度的 Pod。堆顶是优先级最高的 Pod。
activeQ *heap.Heap
// podBackoffQ 是一个按退避到期时间排序的堆。已完成退避的 Pod 会从此堆中弹出,然后进入 activeQ。
podBackoffQ *heap.Heap
// unschedulablePods 存放那些尝试过但被确定为不可调度的 Pod。
unschedulablePods *UnschedulablePods
// Pod 的初始退避时间。
podInitialBackoffDuration time.Duration
// Pod 的最大退避时间。
podMaxBackoffDuration time.Duration
// Pod 可以在 unschedulablePods 队列中停留的最长时间。
podMaxInUnschedulablePodsDuration time.Duration
// schedulingCycle 代表调度周期的序列号,每当一个 Pod 被弹出时递增。
schedulingCycle int64
// moveRequestCycle 缓存了收到移动请求时的调度周期序列号。
// 当收到移动请求时,在此周期及之前被判为不可调度的 Pod 将被移回 activeQueue。
moveRequestCycle int64
// 存储集群事件与关心这些事件的插件名称之间的映射。
clusterEventMap map[framework.ClusterEvent]sets.String
// 存储调度器和对应的已注册的 PreEnqueue 插件之间的映射。
preEnqueuePluginMap map[string][]framework.PreEnqueuePlugin
// 队列是否已关闭的标志。
// 主要用于让 Pop() 在等待项时能够退出其控制循环。
closed bool
// 用于列出命名空间,主要用于亲和性计算。
nsLister listersv1.NamespaceLister
// 用于记录指标。
metricsRecorder metrics.MetricAsyncRecorder
// 运行插件时记录指标的采样百分比。
pluginMetricsSamplePercent int
// 字段顺序相比源码重新组织过,省略了部分字段......
}这三个子队列各司其职:
activeQ *heap.Heap: 活动队列。这是一个heap.Heap实例,是调度器主要的工作队列。所有新加入且准备就绪的 Pod 都会被放入这里,并根据其优先级排序,堆顶始终是优先级最高的 Pod。podBackoffQ *heap.Heap: 退避队列。同样是一个heap.Heap实例,用于存放调度失败后需要暂时“冷静”一下的 Pod。这个堆的排序依据是 Pod 的退避过期时间,这可以防止调度器对暂时无法满足条件的 Pod 进行过于频繁且无效的重试。unschedulablePods *UnschedulablePods: 不可调度队列。这是一个UnschedulablePods实例,其内部是一个 map 结构。它用于存放那些经过调度评估后,被确定在当前集群状态下无法调度的 Pod。这些 Pod 会在此“休眠”,直到集群发生某些可能使其变得可调度的事件时才会被唤醒。
activeQ 和 podBackoffQ 的类型都是已经介绍过的 Heap 堆结构,即优先级队列。而 unschedulablePods 底层则是一个 map ,其实现较为简单(无非就是对 map 的增删改查):
type UnschedulablePods struct {
// podInfoMap 是一个以 Pod 全名(namespace/name)为 key,QueuedPodInfo 指针为值的 map。
podInfoMap map[string]*framework.QueuedPodInfo
keyFunc func(*v1.Pod) string
// 用于记录不可调度 Pod 和被 PreEnqueue 插件阻止的 Pod 的数量。
unschedulableRecorder, gatedRecorder metrics.MetricRecorder
}
// addOrUpdate 向 unschedulablePods 中添加或更新一个 Pod。
func (u *UnschedulablePods) addOrUpdate(pInfo *framework.QueuedPodInfo) {
podID := u.keyFunc(pInfo.Pod)
if _, exists := u.podInfoMap[podID]; !exists {
// 如果是新添加,则增加相应的度量计数。
if pInfo.Gated && u.gatedRecorder != nil {
u.gatedRecorder.Inc()
} else if !pInfo.Gated && u.unschedulableRecorder != nil {
u.unschedulableRecorder.Inc()
}
}
u.podInfoMap[podID] = pInfo
}
// delete 从 unschedulablePods 中删除一个 Pod,并更新度量计数。
func (u *UnschedulablePods) delete(pod *v1.Pod, gated bool) {
podID := u.keyFunc(pod)
if _, exists := u.podInfoMap[podID]; exists {
if gated && u.gatedRecorder != nil {
u.gatedRecorder.Dec()
} else if !gated && u.unschedulableRecorder != nil {
u.unschedulableRecorder.Dec()
}
}
delete(u.podInfoMap, podID)
}
// get 根据 Pod 对象从 unschedulablePods 中查找并返回对应的 QueuedPodInfo。
func (u *UnschedulablePods) get(pod *v1.Pod) *framework.QueuedPodInfo {
podKey := u.keyFunc(pod)
if pInfo, exists := u.podInfoMap[podKey]; exists {
return pInfo
}
return nil
}
// clear 清空 unschedulablePods 中的所有元素。
func (u *UnschedulablePods) clear() {
u.podInfoMap = make(map[string]*framework.QueuedPodInfo)
if u.unschedulableRecorder != nil {
u.unschedulableRecorder.Clear()
}
if u.gatedRecorder != nil {
u.gatedRecorder.Clear()
}
}调度队列的初始化
在分析 PriorityQueue 的具体方法实现前,有必要先了解其初始化逻辑。其中,activeQ 与 podBackoffQ 的初始化最为关键,而 unschedulablePods 部分过于简单,不再赘述:
func NewSchedulingQueue(
lessFn framework.LessFunc,
informerFactory informers.SharedInformerFactory,
opts ...Option) SchedulingQueue {
return NewPriorityQueue(lessFn, informerFactory, opts...)
}
func NewPriorityQueue(
lessFn framework.LessFunc,
informerFactory informers.SharedInformerFactory,
opts ...Option,
) *PriorityQueue {
// 使用默认配置初始化 options。
options := defaultPriorityQueueOptions
if options.podLister == nil {
options.podLister = informerFactory.Core().V1().Pods().Lister()
}
// 应用所有传入的可选配置。
for _, opt := range opts {
opt(&options)
}
// 定义用于 activeQ 的比较函数。
comp := func(podInfo1, podInfo2 interface{}) bool {
pInfo1 := podInfo1.(*framework.QueuedPodInfo)
pInfo2 := podInfo2.(*framework.QueuedPodInfo)
return lessFn(pInfo1, pInfo2)
}
// 创建并初始化 PriorityQueue 实例。
pq := &PriorityQueue{
nominator: newPodNominator(options.podLister),
clock: options.clock,
stop: make(chan struct{}),
podInitialBackoffDuration: options.podInitialBackoffDuration,
podMaxBackoffDuration: options.podMaxBackoffDuration,
podMaxInUnschedulablePodsDuration: options.podMaxInUnschedulablePodsDuration,
// activeQ 的初始化,调用带指标计数器的构造函数初始化一个堆结构,比较函数使用的是 comp。
activeQ: heap.NewWithRecorder(podInfoKeyFunc, comp, metrics.NewActivePodsRecorder()),
unschedulablePods: newUnschedulablePods(metrics.NewUnschedulablePodsRecorder(), metrics.NewGatedPodsRecorder()),
moveRequestCycle: -1,
clusterEventMap: options.clusterEventMap,
// PreEnqueue 插件,由调用方(调度器)传递进来初始化,是调度框架的扩展点之一,用来控制 Pod 是否允许入队。
preEnqueuePluginMap: options.preEnqueuePluginMap,
metricsRecorder: options.metricsRecorder,
pluginMetricsSamplePercent: options.pluginMetricsSamplePercent,
}
pq.cond.L = &pq.lock
// 同理为 backoffQ 创建一个堆结构,使用基于退避完成时间的比较函数。
pq.podBackoffQ = heap.NewWithRecorder(podInfoKeyFunc, pq.podsCompareBackoffCompleted, metrics.NewBackoffPodsRecorder())
pq.nsLister = informerFactory.Core().V1().Namespaces().Lister()
return pq
}activeQ 的比较函数,即 lessFn framework.LessFunc 是由调用方传递过来的,传递的是调度框架的 QueueSort 扩展点的 Less 方法,对应如图的红色部分:
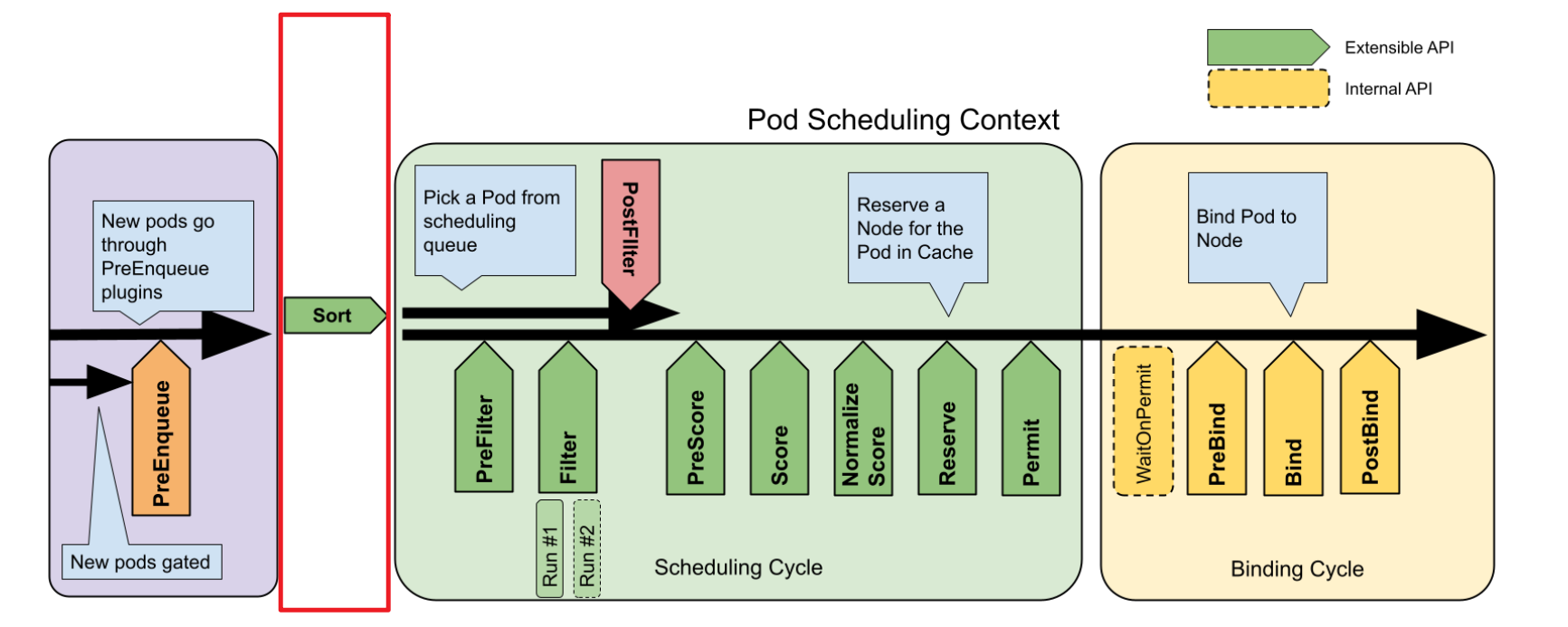
当前默认实现是 PrioritySort 插件,这里直接贴出实现方法,后续文章我们还会再详细分析调度框架的实现:
func (pl *PrioritySort) Less(pInfo1, pInfo2 *framework.QueuedPodInfo) bool {
p1 := corev1helpers.PodPriority(pInfo1.Pod)
p2 := corev1helpers.PodPriority(pInfo2.Pod)
return (p1 > p2) || (p1 == p2 && pInfo1.Timestamp.Before(pInfo2.Timestamp))
}代码意图较为明确,排序逻辑主要两个:
- 主排序条件:Pod 的 priority 值。数值越大,优先级越高。
- 次排序条件:当优先级相同时,使用 Pod 入队时间
pInfo1.Timestamp来排序,先入队的 Pod 优先调度。
这套逻辑也完全符合我们的直觉:定义了更高 PriorityClass 的 Pod 应该先调度,而在优先级一致时,就按“先来先服务”的顺序来保证公平性。
再看到 podBackoffQ 的比较函数:
func (p *PriorityQueue) podsCompareBackoffCompleted(podInfo1, podInfo2 interface{}) bool {
pInfo1 := podInfo1.(*framework.QueuedPodInfo)
pInfo2 := podInfo2.(*framework.QueuedPodInfo)
bo1 := p.getBackoffTime(pInfo1)
bo2 := p.getBackoffTime(pInfo2)
return bo1.Before(bo2)
}
// getBackoffTime 计算并返回一个 Pod 的退避完成时间。
func (p *PriorityQueue) getBackoffTime(podInfo *framework.QueuedPodInfo) time.Time {
duration := p.calculateBackoffDuration(podInfo)
// 将 backoff 时间加到 Pod 入队时间 podInfo.Timestamp 上,得到 backoff 完成时间
backoffTime := podInfo.Timestamp.Add(duration)
return backoffTime
}
// calculateBackoffDuration 根据 Pod 的尝试次数计算退避时长(指数退避)。
func (p *PriorityQueue) calculateBackoffDuration(podInfo *framework.QueuedPodInfo) time.Duration {
duration := p.podInitialBackoffDuration
for i := 1; i < podInfo.Attempts; i++ {
if duration > p.podMaxBackoffDuration-duration {
return p.podMaxBackoffDuration
}
duration += duration
}
return duration
}最终效果就是退避完成时间最早、尝试次数少的 Pod 优先级最高,以此保证指数退避机制和调度公平性。
调度队列的具体实现
Add 添加 Pod
作用:将新 Pod 插入到调度队列,等待调度。
func (p *PriorityQueue) Add(pod *v1.Pod) error {
p.lock.Lock()
defer p.lock.Unlock()
// 把一个 Pod 包装成可进入内部队列的 QueuedPodInfo 对象,并初始化各种时间戳与标记,
// 包括当前入队时间和第一次尝试调度的时间都会被设置为当前时间。
pInfo := p.newQueuedPodInfo(pod)
gated := pInfo.Gated
// 尝试将 Pod 添加到 activeQ。
if added, err := p.addToActiveQ(pInfo); !added {
return err
}
// 如果 Pod 已存在于 unschedulablePods,则记录错误并从中删除。
if p.unschedulablePods.get(pod) != nil {
klog.ErrorS(nil, "Error: pod is already in the unschedulable queue", "pod", klog.KObj(pod))
p.unschedulablePods.delete(pod, gated)
}
// 如果 Pod 已存在于 backoffQ,则记录错误并从中删除。
if err := p.podBackoffQ.Delete(pInfo); err == nil {
klog.ErrorS(nil, "Error: pod is already in the podBackoff queue", "pod", klog.KObj(pod))
}
klog.V(5).InfoS("Pod moved to an internal scheduling queue", "pod", klog.KObj(pod), "event", PodAdd, "queue", activeQName)
metrics.SchedulerQueueIncomingPods.WithLabelValues("active", PodAdd).Inc()
p.addNominatedPodUnlocked(pInfo.PodInfo, nil)
// 唤醒可能正在等待的 Pop() 调用。
p.cond.Broadcast()
return nil
}具体流程分为三步:
通过
addToActiveQ尝试把 Pod 放进 activeQ。- 如果返回
added=false, err=nil:表示 Pod 被 PreEnqueue 插件拦下,并放入到 unschedulablePods 中,Add仍返回 nil(这是“业务正常”的一种结果)。 - 如果返回
added=false, err!=nil:表示放入 activeQ 真出错了(例如堆结构异常),Add就会直接返回这个错误。 - 如果
added=true:表明进入 activeQ 成功,继续后续整理工作。
- 如果返回
去重/清理:
- 如果同一个 Pod 之前就在 unschedulablePods,先删掉,避免重复。
- 如果它在 podBackoffQ 里,也删除。
这两个删除是幂等性与一致性处理:一个 Pod 只应该出现在一个子队列中。
通过
p.cond.Broadcast()广播条件变量,唤醒可能在等待新任务的调度循环。
涉及到的 addToActiveQ 方法如下:
func (p *PriorityQueue) addToActiveQ(pInfo *framework.QueuedPodInfo) (bool, error) {
// 首先运行 PreEnqueue 插件,如果失败,pInfo.Gated 会被设为 true。
pInfo.Gated = !p.runPreEnqueuePlugins(context.Background(), pInfo)
if pInfo.Gated {
// 如果 Pod 未通过 PreEnqueue 插件,则将其添加到 unschedulablePods。
p.unschedulablePods.addOrUpdate(pInfo)
return false, nil
}
// 如果通过,则添加到 activeQ。
if err := p.activeQ.Add(pInfo); err != nil {
klog.ErrorS(err, "Error adding pod to the active queue", "pod", klog.KObj(pInfo.Pod))
return false, err
}
return true, nil
}运行 PreEnqueue 插件的方法,会依序运行当前调度配置下该 Pod 对应的 SchedulerName (默认值为 default-scheduler )所注册的全部 PreEnqueue 插件,只有全成功才能返回 true (只要一个插件拒绝,就无法入队):
func (p *PriorityQueue) runPreEnqueuePlugins(ctx context.Context, pInfo *framework.QueuedPodInfo) bool {
var s *framework.Status
pod := pInfo.Pod
startTime := time.Now()
defer func() {
metrics.FrameworkExtensionPointDuration.WithLabelValues(preEnqueue, s.Code().String(), pod.Spec.SchedulerName).Observe(metrics.SinceInSeconds(startTime))
}()
// 根据百分比抽样决定是否给每个插件记录单独耗时(避免指标过量)。
shouldRecordMetric := rand.Intn(100) < p.pluginMetricsSamplePercent
// 遍历对应 SchedulerName 的所有 PreEnqueue 插件列表
for _, pl := range p.preEnqueuePluginMap[pod.Spec.SchedulerName] {
// 执行单个 PreEnqueue 插件
s = p.runPreEnqueuePlugin(ctx, pl, pod, shouldRecordMetric)
if s.IsSuccess() {
continue
}
// 如果插件返回失败,则为 Pod 记录下失败的插件名称。
pInfo.UnschedulablePlugins.Insert(pl.Name())
metrics.UnschedulableReason(pl.Name(), pod.Spec.SchedulerName).Inc()
if s.Code() == framework.Error {
klog.ErrorS(s.AsError(), "Unexpected error running PreEnqueue plugin", "pod", klog.KObj(pod), "plugin", pl.Name())
} else {
klog.V(5).InfoS("Status after running PreEnqueue plugin", "pod", klog.KObj(pod), "plugin", pl.Name(), "status", s)
}
return false
}
return true
}
func (p *PriorityQueue) runPreEnqueuePlugin(ctx context.Context, pl framework.PreEnqueuePlugin, pod *v1.Pod, shouldRecordMetric bool) *framework.Status {
// pl 作为 framework.PreEnqueuePlugin 即调度框架的 PreEnqueue 插件实现,
// 调用其 PreEnqueue 方法即可进行入队判断。
if !shouldRecordMetric {
return pl.PreEnqueue(ctx, pod)
}
startTime := p.clock.Now()
s := pl.PreEnqueue(ctx, pod)
p.metricsRecorder.ObservePluginDurationAsync(preEnqueue, pl.Name(), s.Code().String(), p.clock.Since(startTime).Seconds())
return s
}这里对应的调度框架的 PreEnqueue 扩展点,如图红色部分:
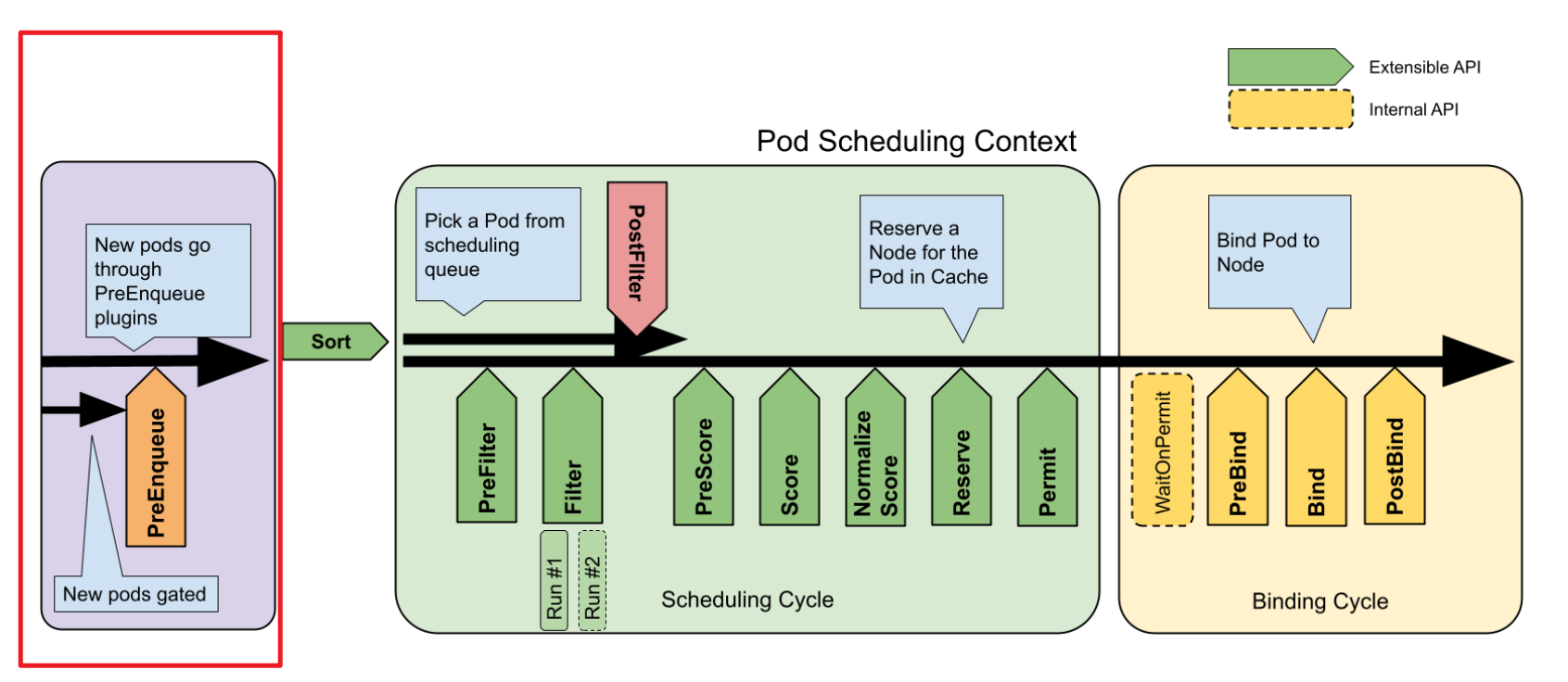
也就是说,目前调度框架中的两个扩展点:PreEnqueue 和 QueueSort (图中的 Sort )都是在调度队列内部调用的。
Activate 激活 Pod
作用:把 Pod 从 unschedulablePods 或 backoffQ 移到 activeQ,重新进入调度流程。
func (p *PriorityQueue) Activate(pods map[string]*v1.Pod) {
p.lock.Lock()
defer p.lock.Unlock()
activated := false
// 逻辑比较清晰,一个个激活。
for _, pod := range pods {
if p.activate(pod) {
activated = true
}
}
// 如果至少有一个成功激活,就把条件变量广播唤醒调度循环。
if activated {
p.cond.Broadcast()
}
}
func (p *PriorityQueue) activate(pod *v1.Pod) bool {
// 检查 Pod 是否已在 activeQ 中,如果是,则无需激活。
if _, exists, _ := p.activeQ.Get(newQueuedPodInfoForLookup(pod)); exists {
return false
}
var pInfo *framework.QueuedPodInfo
// 检查 Pod 是否在 unschedulablePods 或 backoffQ 中,有的话就提取出来,都没有就可以退出了。
if pInfo = p.unschedulablePods.get(pod); pInfo == nil {
if obj, exists, _ := p.podBackoffQ.Get(newQueuedPodInfoForLookup(pod)); !exists {
klog.ErrorS(nil, "To-activate pod does not exist in unschedulablePods or backoffQ", "pod", klog.KObj(pod))
return false
} else {
pInfo = obj.(*framework.QueuedPodInfo)
}
}
// 确保安全的多余检查。
if pInfo == nil {
klog.ErrorS(nil, "Internal error: cannot obtain pInfo")
return false
}
gated := pInfo.Gated
// 尝试将 Pod 添加到 activeQ ,即激活。
if added, _ := p.addToActiveQ(pInfo); !added {
return false
}
// 激活成功,则从 unschedulablePods 和 backoffQ 中删除该 Pod。
p.unschedulablePods.delete(pInfo.Pod, gated)
p.podBackoffQ.Delete(pInfo)
metrics.SchedulerQueueIncomingPods.WithLabelValues("active", ForceActivate).Inc()
p.addNominatedPodUnlocked(pInfo.PodInfo, nil)
return true
}激活的流程实际和 Add 方法一致(addToActiveQ),理解了 Add 方法,自然理解了 Activate 方法。
AddUnschedulableIfNotPresent 重新入队不可调度 Pod
作用:当 Pod 在一次调度中失败时,把它放回不可调度队列以便后续重试。
func (p *PriorityQueue) AddUnschedulableIfNotPresent(pInfo *framework.QueuedPodInfo, podSchedulingCycle int64) error {
p.lock.Lock()
defer p.lock.Unlock()
pod := pInfo.Pod
// 检查 Pod 当前是否已在任何队列中,如果是,则返回错误。
// 因为 Pod 目前不应该出现在任何队列中
if p.unschedulablePods.get(pod) != nil {
return fmt.Errorf("Pod %v is already present in unschedulable queue", klog.KObj(pod))
}
if _, exists, _ := p.activeQ.Get(pInfo); exists {
return fmt.Errorf("Pod %v is already present in the active queue", klog.KObj(pod))
}
if _, exists, _ := p.podBackoffQ.Get(pInfo); exists {
return fmt.Errorf("Pod %v is already present in the backoff queue", klog.KObj(pod))
}
// 刷新时间戳,因为 Pod 是被重新添加的。
pInfo.Timestamp = p.clock.Now()
for plugin := range pInfo.UnschedulablePlugins {
metrics.UnschedulableReason(plugin, pInfo.Pod.Spec.SchedulerName).Inc()
}
// 如果最近调用过 MoveAllToActiveOrBackoffQueue() ,则会更新 moveRequestCycle,
// 就有可能出现 moveRequestCycle >= podSchedulingCycle 的情况,此时应该移入 podBackoffQ,
// 否则才移入 unschedulablePods。
if p.moveRequestCycle >= podSchedulingCycle {
if err := p.podBackoffQ.Add(pInfo); err != nil {
return fmt.Errorf("error adding pod %v to the backoff queue: %v", klog.KObj(pod), err)
}
klog.V(5).InfoS("Pod moved to an internal scheduling queue", "pod", klog.KObj(pod), "event", ScheduleAttemptFailure, "queue", backoffQName)
metrics.SchedulerQueueIncomingPods.WithLabelValues("backoff", ScheduleAttemptFailure).Inc()
} else {
p.unschedulablePods.addOrUpdate(pInfo)
klog.V(5).InfoS("Pod moved to an internal scheduling queue", "pod", klog.KObj(pod), "event", ScheduleAttemptFailure, "queue", unschedulablePods)
metrics.SchedulerQueueIncomingPods.WithLabelValues("unschedulable", ScheduleAttemptFailure).Inc()
}
p.addNominatedPodUnlocked(pInfo.PodInfo, nil)
return nil
}这里会有一个 p.moveRequestCycle >= podSchedulingCycle 的判断,如果 Pod 当前尝试调度的周期已经落后或等于上一次 moveRequest 的周期,说明调度器调用过了 MoveAllToActiveOrBackoffQueue()(下面会再讲,发送这种情况可能是调用接口抢锁晚了而已),则该 Pod 也应该从 unschedulablePods 移动出来,因此把 Pod 放入 podBackoffQ,开始退避计时,等待一段退避时间后再尝试激活。
SchedulingCycle 获取调度周期编号
作用:返回当前调度循环的编号,每次取出 Pod (Pop) 时都会自增。
// 过于简单,不描述了
func (p *PriorityQueue) SchedulingCycle() int64 {
p.lock.RLock()
defer p.lock.RUnlock()
return p.schedulingCycle
}Pop 弹出 Pod(调度入口)
作用:移除并返回队首 Pod;若队列为空则阻塞等待,这是调度器的核心入口。
func (p *PriorityQueue) Pop() (*framework.QueuedPodInfo, error) {
p.lock.Lock()
defer p.lock.Unlock()
// 如果 activeQ 为空,则循环等待。
for p.activeQ.Len() == 0 {
// 如果队列已关闭,则退出循环并返回错误。
if p.closed {
return nil, fmt.Errorf(queueClosed)
}
// 在条件变量上等待,直到被唤醒。
p.cond.Wait()
}
// 从 activeQ 弹出 Pod。
obj, err := p.activeQ.Pop()
if err != nil {
return nil, err
}
pInfo := obj.(*framework.QueuedPodInfo)
pInfo.Attempts++
// 调度周期计数+1
p.schedulingCycle++
return pInfo, nil
}事先熟悉了底层结构后,该方法很好理解,直接调用底层结构 Heap 的 Pop 方法取出堆顶 Pod ,也就是优先级最高的 Pod 。
Update 更新 Pod
作用:在队列中更新 Pod 信息,不存在则插入。
// Update 方法处理 Pod 的更新事件,逻辑比较复杂:
// 1. 如果 Pod 在 activeQ 或 podBackoffQ 中,直接更新它。
// 2. 如果 Pod 在 unschedulablePods 中,检查更新是否使其可调度(isPodUpdated)。
// - 如果是,则将其移至 activeQ 或 podBackoffQ。
// - 如果否,则仅更新其在 unschedulablePods 中的信息。
// 3. 如果 Pod 不在任何队列中,则将其作为一个新 Pod 添加到 activeQ。
func (p *PriorityQueue) Update(oldPod, newPod *v1.Pod) error {
p.lock.Lock()
defer p.lock.Unlock()
if oldPod != nil {
oldPodInfo := newQueuedPodInfoForLookup(oldPod)
// Case 1: Pod 在 activeQ 中。
if oldPodInfo, exists, _ := p.activeQ.Get(oldPodInfo); exists {
pInfo := updatePod(oldPodInfo, newPod)
p.updateNominatedPodUnlocked(oldPod, pInfo.PodInfo)
return p.activeQ.Update(pInfo)
}
// Case 1: Pod 在 podBackoffQ 中。
if oldPodInfo, exists, _ := p.podBackoffQ.Get(oldPodInfo); exists {
pInfo := updatePod(oldPodInfo, newPod)
p.updateNominatedPodUnlocked(oldPod, pInfo.PodInfo)
return p.podBackoffQ.Update(pInfo)
}
}
// Case 2: Pod 在 unschedulablePods 中。
if usPodInfo := p.unschedulablePods.get(newPod); usPodInfo != nil {
pInfo := updatePod(usPodInfo, newPod)
p.updateNominatedPodUnlocked(oldPod, pInfo.PodInfo)
// 检查 Pod 的更新是否可能使其变得可调度。
if isPodUpdated(oldPod, newPod) {
gated := usPodInfo.Gated
if p.isPodBackingoff(usPodInfo) {
// 如果仍在退避期,则加入到 podBackoffQ。
if err := p.podBackoffQ.Add(pInfo); err != nil {
return err
}
p.unschedulablePods.delete(usPodInfo.Pod, gated)
} else {
// 不在退避期,则激活到 activeQ。
if added, err := p.addToActiveQ(pInfo); !added {
return err
}
p.unschedulablePods.delete(usPodInfo.Pod, gated)
p.cond.Broadcast()
}
} else {
p.unschedulablePods.addOrUpdate(pInfo)
}
return nil
}
// Case 3: Pod 不在任何队列中。
pInfo := p.newQueuedPodInfo(newPod)
if added, err := p.addToActiveQ(pInfo); !added {
return err
}
p.addNominatedPodUnlocked(pInfo.PodInfo, nil)
p.cond.Broadcast()
return nil
}
func isPodUpdated(oldPod, newPod *v1.Pod) bool {
// 把和调度无关的字段清理掉
strip := func(pod *v1.Pod) *v1.Pod {
p := pod.DeepCopy()
p.ResourceVersion = "" // 每次更新都会变,但对调度没意义
p.Generation = 0 // 类似,版本计数,调度不关心
p.Status = v1.PodStatus{} // Pod 的 Status(Running/Failed 等)调度器不依赖
p.ManagedFields = nil // 管理字段(server 端 apply 用),与调度无关
p.Finalizers = nil // Finalizer 与调度也无关
return p
}
// 去掉上述噪音字段后,比较两个 Pod 是否完全相同
return !reflect.DeepEqual(strip(oldPod), strip(newPod))
}Update 的核心就是 “能就地更新就就地更新、能推进就推进(推进到 activeQ 或 podBackoffQ)” 。
Delete 删除 Pod
作用:将指定 Pod 从队列中移除。
func (p *PriorityQueue) Delete(pod *v1.Pod) error {
p.lock.Lock()
defer p.lock.Unlock()
p.deleteNominatedPodIfExistsUnlocked(pod)
pInfo := newQueuedPodInfoForLookup(pod)
// 尝试从 activeQ 删除。
if err := p.activeQ.Delete(pInfo); err != nil {
// 如果 activeQ 删除失败,则尝试从 podBackoffQ 和 unschedulablePods 删除。
p.podBackoffQ.Delete(pInfo)
if pInfo = p.unschedulablePods.get(pod); pInfo != nil {
p.unschedulablePods.delete(pod, pInfo.Gated)
}
}
return nil
}Delete 也很简单,就是支持从任一队列中删除 Pod,它假设 Pod 只存在于一个队列中。
MoveAllToActiveOrBackoffQueue 批量迁移 Pod
作用:根据事件(如资源变化)把 unschedulablePods 中的 Pod 批量移到 activeQ 或 backoffQ。
func (p *PriorityQueue) MoveAllToActiveOrBackoffQueue(event framework.ClusterEvent, preCheck PreEnqueueCheck) {
p.lock.Lock()
defer p.lock.Unlock()
p.moveAllToActiveOrBackoffQueue(event, preCheck)
}
func (p *PriorityQueue) moveAllToActiveOrBackoffQueue(event framework.ClusterEvent, preCheck PreEnqueueCheck) {
// 把所有的 unschedulablePods map 变成 QueuedPodInfo 切片
unschedulablePods := make([]*framework.QueuedPodInfo, 0, len(p.unschedulablePods.podInfoMap))
for _, pInfo := range p.unschedulablePods.podInfoMap {
if preCheck == nil || preCheck(pInfo.Pod) {
unschedulablePods = append(unschedulablePods, pInfo)
}
}
p.movePodsToActiveOrBackoffQueue(unschedulablePods, event)
}
func (p *PriorityQueue) movePodsToActiveOrBackoffQueue(podInfoList []*framework.QueuedPodInfo, event framework.ClusterEvent) {
activated := false
for _, pInfo := range podInfoList {
// 检查 Pod 是否真的能从这个事件中受益。
if len(pInfo.UnschedulablePlugins) != 0 && !p.podMatchesEvent(pInfo, event) {
continue
}
pod := pInfo.Pod
// 根据 Pod 是否在退避期,决定移入 podBackoffQ 还是 activeQ。
if p.isPodBackingoff(pInfo) {
if err := p.podBackoffQ.Add(pInfo); err != nil {
klog.ErrorS(err, "Error adding pod to the backoff queue", "pod", klog.KObj(pod))
} else {
p.unschedulablePods.delete(pod, pInfo.Gated)
}
} else {
gated := pInfo.Gated
if added, _ := p.addToActiveQ(pInfo); added {
activated = true
p.unschedulablePods.delete(pod, gated)
}
}
}
// 更新 moveRequestCycle,以便 AddUnschedulableIfNotPresent 能做出正确判断。
p.moveRequestCycle = p.schedulingCycle
if activated {
p.cond.Broadcast()
}
}其实到这里会发现,很多都是类似的逻辑,比如根据 Pod 是否在退避期,决定移入 podBackoffQ 还是 activeQ 和之前的 Update 方法是一样的。
在处理完所有 unschedulablePods 中的 Pod 后,便会把 moveRequestCycle 变为当前调度周期,也就是说,在当前调度周期以及之前的 Pod ,都会被标记为需要从 unschedulablePods 移动出来的,这里就能和 AddUnschedulableIfNotPresent 对应上了。
关于检查 Pod 是否真的能从这个事件中受益,也就是判断这次发生的 clusterEvent 是否可能让不可调度的 Pod 重新变得可调度,其实现如下:
func (p *PriorityQueue) podMatchesEvent(podInfo *framework.QueuedPodInfo, clusterEvent framework.ClusterEvent) bool {
if clusterEvent.IsWildCard() {
return true
}
// 查找全局的 clusterEventMap 注册表。
for evt, nameSet := range p.clusterEventMap {
// 首先,验证两个 ClusterEvent 是否匹配。
evtMatch := evt.IsWildCard() ||
(evt.Resource == clusterEvent.Resource && evt.ActionType&clusterEvent.ActionType != 0)
// 其次,验证导致 Pod 不可调度的插件名称是否在关心此事件的插件集合中。
if evtMatch && intersect(nameSet, podInfo.UnschedulablePlugins) {
return true
}
}
return false
}
// intersect 的作用其实就是判断 Pod 当前卡住的插件,是否在关心该事件的插件集合里。
func intersect(x, y sets.String) bool {
if len(x) > len(y) {
x, y = y, x
}
for v := range x {
if y.Has(v) {
return true
}
}
return false
}这里可能需要举个例子:
假设有一个 Pod,它因为 NodeAffinity 插件检查失败而不可调度,则:
podInfo.UnschedulablePlugins = {"NodeAffinity"}此时调度器收到一个事件:某个 Node 的 Label 发生了更新:
clusterEvent = {Resource: Node, ActionType: UpdateNodeLabel}再看调度器全局注册的 clusterEventMap 里,可能也有这样一条:
{Resource: Node, ActionType: UpdateNodeLabel} -> {"NodeAffinity"}对应到 podMatchesEvent 的匹配过程如下:
- 事件匹配
evt.Resource == clusterEvent.Resource(都是 Node,匹配通过)evt.ActionType & clusterEvent.ActionType != 0(都是 UpdateNodeLabel,匹配通过)
- 插件匹配
nameSet = {"NodeAffinity"}podInfo.UnschedulablePlugins = {"NodeAffinity"}- 两者交集不为空,
intersect匹配通过
因此最终 podMatchesEvent 返回 true,说明这个 Pod 确实有机会在 Node label 更新后重新调度。
利用这种事件机制,就能避免不可调度队列中的 Pod 被“无效唤醒”。
AssignedPodAdded 已分配 Pod 新增事件
作用:当 Pod 成功绑定到节点时触发,用于唤醒可能因其而可调度的 Pending Pod。
func (p *PriorityQueue) AssignedPodAdded(pod *v1.Pod) {
p.lock.Lock()
// 找出 unschedulablePods 中所有与新 Pod 匹配亲和性的 Pod,并移动它们
p.movePodsToActiveOrBackoffQueue(p.getUnschedulablePodsWithMatchingAffinityTerm(pod), AssignedPodAdd)
p.lock.Unlock()
}
func (p *PriorityQueue) getUnschedulablePodsWithMatchingAffinityTerm(pod *v1.Pod) []*framework.QueuedPodInfo {
nsLabels := interpodaffinity.GetNamespaceLabelsSnapshot(pod.Namespace, p.nsLister)
var podsToMove []*framework.QueuedPodInfo
for _, pInfo := range p.unschedulablePods.podInfoMap {
for _, term := range pInfo.RequiredAffinityTerms {
if term.Matches(pod, nsLabels) {
podsToMove = append(podsToMove, pInfo)
break
}
}
}
return podsToMove
}当一个 Pod 被成功分配到节点/加入集群时(assigned/added),调度器要检查是否有那些因为 Pod-Affinity/AntiAffinity 条件而被卡住的待调度 Pod,因为新加的这个 Pod 可能满足它们的 Affinity 条件,能把它们从 unschedulablePods 唤醒并重新尝试调度。
movePodsToActiveOrBackoffQueue 方法已经讲过了。对于 getUnschedulablePodsWithMatchingAffinityTerm 方法,也好理解:找出所有因缺少 PodAffinity/AntiAffinity 匹配对象而处于不可调度队列中的 Pod,并判断新加入的 Pod 是否满足它们的 requiredAffinityTerms,如果满足则将这些 Pod 标记为可重试调度。
AssignedPodUpdated 已分配 Pod 更新事件
作用:当已绑定 Pod 信息变化时触发,作用与 AssignedPodAdded 类似。
func (p *PriorityQueue) AssignedPodUpdated(pod *v1.Pod) {
p.lock.Lock()
if isPodResourcesResizedDown(pod) {
// 如果 Pod 资源被调小,可能会释放资源,使很多 Pod 变得可调度,因此移动所有 Pod。
p.moveAllToActiveOrBackoffQueue(AssignedPodUpdate, nil)
} else {
// 否则,只移动那些与此 Pod 有亲和性关系的 Pod。
p.movePodsToActiveOrBackoffQueue(p.getUnschedulablePodsWithMatchingAffinityTerm(pod), AssignedPodUpdate)
}
p.lock.Unlock()
}
func isPodResourcesResizedDown(pod *v1.Pod) bool {
if utilfeature.DefaultFeatureGate.Enabled(features.InPlacePodVerticalScaling) {
// TODO(vinaykul,wangchen615,InPlacePodVerticalScaling): Fix this to determine when a
// pod is truly resized down (might need oldPod if we cannot determine from Status alone)
if pod.Status.Resize == v1.PodResizeStatusInProgress {
return true
}
}
return false
}AssignedPodUpdated 和 AssignedPodAdded 的实现其实是一样的,只是多了一个就地垂直伸缩(InPlacePodVerticalScaling)的特性门控判断,如果 Pod 资源(CPU或内存)被调低了,则尝试移动所有不可调度的 Pod 。
PendingPods 获取待调度 Pod 列表
作用:返回所有处于 Pending 状态的 Pod 及调试信息。
func (p *PriorityQueue) PendingPods() ([]*v1.Pod, string) {
p.lock.RLock()
defer p.lock.RUnlock()
var result []*v1.Pod
// 从三个子队列中收集所有 Pod。
for _, pInfo := range p.activeQ.List() {
result = append(result, pInfo.(*framework.QueuedPodInfo).Pod)
}
for _, pInfo := range p.podBackoffQ.List() {
result = append(result, pInfo.(*framework.QueuedPodInfo).Pod)
}
for _, pInfo := range p.unschedulablePods.podInfoMap {
result = append(result, pInfo.Pod)
}
return result, fmt.Sprintf("activeQ:%v; backoffQ:%v; unschedulablePods:%v", p.activeQ.Len(), p.podBackoffQ.Len(), len(p.unschedulablePods.podInfoMap))
}就是把三个子队列的 Pod 放到一起返回(在任何队列中存在的 Pod,不论何原因,都可认为是 “Pending” 的),比较简单。
Close 关闭调度队列
作用:关闭队列。
func (p *PriorityQueue) Close() {
p.lock.Lock()
defer p.lock.Unlock()
// 关闭 stop channel,通知后台 goroutine 退出。
close(p.stop)
p.closed = true
// 唤醒可能阻塞在 Pop() 的 goroutine,使其能够检查到 closed 标志并退出。
p.cond.Broadcast()
}Run 启动调度队列后台逻辑
作用:启动后台 goroutine,处理 backoff、定时器等管理逻辑。
func (p *PriorityQueue) Run() {
// 每秒钟检查一次 podBackoffQ,将退避完成的 Pod 移到 activeQ。
go wait.Until(p.flushBackoffQCompleted, 1.0*time.Second, p.stop)
// 每 30 秒检查一次 unschedulablePods,防止 Pod 在其中停留过久。
go wait.Until(p.flushUnschedulablePodsLeftover, 30*time.Second, p.stop)
}先来看看 flushBackoffQCompleted 的处理:
func (p *PriorityQueue) flushBackoffQCompleted() {
p.lock.Lock()
defer p.lock.Unlock()
activated := false
for {
// 仅查看 podBackoffQ 堆顶的 Pod,但不弹出。
// 这里也是唯一一次会使用到 Peek 的地方。
rawPodInfo := p.podBackoffQ.Peek()
if rawPodInfo == nil {
break
}
pInfo := rawPodInfo.(*framework.QueuedPodInfo)
pod := pInfo.Pod
// 如果堆顶的 Pod 仍在退避期,则停止处理,因为堆是按退避完成时间排序的(堆顶 Pod 仍在退避,那么其余所有都在退避)。
if p.isPodBackingoff(pInfo) {
break
}
// 弹出退避完成的 Pod。
_, err := p.podBackoffQ.Pop()
if err != nil {
klog.ErrorS(err, "Unable to pop pod from backoff queue despite backoff completion", "pod", klog.KObj(pod))
break
}
// 将其添加到 activeQ。
if added, _ := p.addToActiveQ(pInfo); added {
klog.V(5).InfoS("Pod moved to an internal scheduling queue", "pod", klog.KObj(pod), "event", BackoffComplete, "queue", activeQName)
metrics.SchedulerQueueIncomingPods.WithLabelValues("active", BackoffComplete).Inc()
activated = true
}
}
if activated {
p.cond.Broadcast()
}
}再来看看 flushUnschedulablePodsLeftover :
func (p *PriorityQueue) flushUnschedulablePodsLeftover() {
p.lock.Lock()
defer p.lock.Unlock()
var podsToMove []*framework.QueuedPodInfo
currentTime := p.clock.Now()
// 遍历 unschedulablePods,找出所有超时的 Pod。
for _, pInfo := range p.unschedulablePods.podInfoMap {
lastScheduleTime := pInfo.Timestamp
if currentTime.Sub(lastScheduleTime) > p.podMaxInUnschedulablePodsDuration {
podsToMove = append(podsToMove, pInfo)
}
}
if len(podsToMove) > 0 {
// 移动这些超时的 Pod。
p.movePodsToActiveOrBackoffQueue(podsToMove, UnschedulableTimeout)
}
}都比较简单,Run 就是启动了两个定时检查的 goroutine,每秒看看 podBackoffQ 的堆顶有没有 Pod 退避期结束了,如果有,把它拉到 activeQ 里,让调度器继续尝试安排。而有些 Pod 卡在 unschedulablePods 里太久了,后台就会每 30 秒会扫一遍,把超时的 Pod 拉出来。所调用到的方法,也都是“老朋友”了。
微信公众号
更多内容请关注微信公众号:gopher云原生