02. kube-scheduler 整体架构
接上回,我们在本地启动了 kube-scheduler 组件,并借助 kwok 管理 Node,从而实现了在无需真实节点的情况下创建 Pod 并模拟绑定的流程。
cmd/kube-scheduler 是启动入口,主要就是解析各类配置参数来初始化 scheduler 调度器对象,也在此实现了多实例下的选举功能。但该模块不是重点,就不过多介绍。
本文主要对 kube-scheduler 的整体架构进行分析,理清各个模块的功能与协作方式,以便后续可以逐个击破。
对于调度器需要重点关注的是 pkg/scheduler 下的代码(仅保留关键):
$ tree pkg/scheduler/
scheduler
├── eventhandlers.go # 事件处理器
├── extender.go # 调度扩展(webhook)
├── framework # 调度框架
├── internal # 调度队列
├── schedule_one.go # 调度流程核心实现(调度周期和绑定周期)
├── scheduler.go # 调度器运行主循环scheduler.go 里面定义调度器的核心结构与实现。内部组合了调度队列、调度框架、调度扩展、事件处理器等多个关键模块,最后启动一个主循环调用 schedule_one.go 执行调度流程。
schedule_one.go 作为最重要的调度流程实现,功能上可以分为 调度周期(schedulingCycle)和 绑定周期(bindingCycle)。
调度队列
调度的本质可以概括为一个“取出 → 评估 → 绑定”的过程:从调度队列中取出一个待调度的 Pod → 执行调度逻辑,评估出最合适的目标节点 → 绑定到目标节点。
所以一个设计良好的调度队列可以很大程度提升调度效率。
在 kube-scheduler 中,调度队列的核心实现位于 pkg/scheduler/internal/ 目录,结构如下:
$ tree pkg/scheduler/internal/
internal
├── cache # 调度缓存
├── heap # 堆结构,作为调度队列的底层结构
└── queue # 调度队列其中 heap 模块提供了调度队列的基础数据结构支持,queue 模块则建立在 heap 之上,实现调度队列核心逻辑,管理所有待调度的 Pod 。
按照优先级和调度状态, queue 划分为三种不同的子队列,即 activeQ 活动队列、podBackoffQ 退避队列和 unschedulablePods 不可调度队列。
当新建一个 Pod 加入到 activeQ 队列后,它可能因为某些原因暂时无法调度,就会被移入 podBackoffQ 或 unschedulablePods 队列,调度器会定期或在外部事件触发下重新尝试调度这些 Pod。
cache 模块则是一个以 Pod 为中心的本地缓存,主要缓存 Pod 和 Node 信息,并聚合调度结果,方便调度器可以高效地进行节点选择与资源评估操作。
例如,在调度过程,调度器会通过 cache 的 AssumePod 操作将一个 Pod 标记为“假设绑定”,表示它预计会成功调度到某个节点,这样就可以“预占”着 Node 的资源。
如果随后收到了来自 API Server 的 Add 事件,就说明调度结果已被确认,Pod 会正式加入已调度列表;但如果长时间没有收到确认事件,说明可能出现了调度失败或通信中断,调度器就会将该 Pod 标记为过期并从缓存中移除。
调度框架
pkg/scheduler/framework 是调度器的调度框架实现。
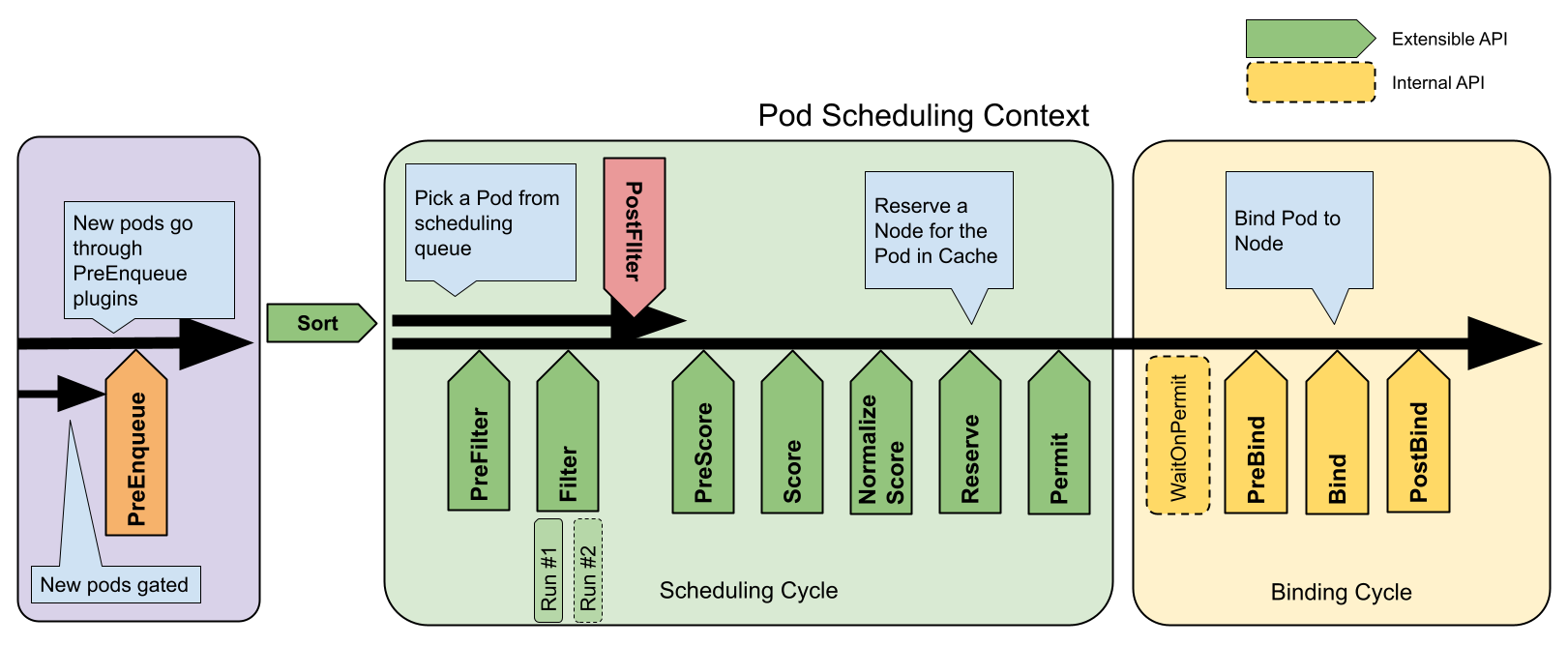
调度框架实际就是把整个调度流程(包括调度周期和绑定周期)细分出各个不同的关键阶段,提供扩展点(go interface 接口)。
所有的调度策略(比如节点亲和性)都以插件的形式提供,只需实现相应的扩展点接口。调度器在执行流程时,会根据调度框架的设计,在对应阶段依次调用所有实现了该扩展点的插件,从而实现策略的灵活扩展与解耦。
在 kube-scheduler 中,有很多这样的调度插件,它们实现了一个或多个扩展点接口:
$ tree pkg/scheduler/framework/plugins/
plugins
├── defaultbinder # 默认且唯一实现了 Bind 绑定扩展点的插件
├── defaultpreemption
├── dynamicresources
├── imagelocality
├── interpodaffinity
├── nodeaffinity
├── nodename
├── nodeports
├── noderesources
├── nodeunschedulable
├── nodevolumelimits
├── podtopologyspread
├── queuesort
├── selectorspread
├── tainttoleration
├── volumebinding
├── volumerestrictions
└── volumezone这些直接内嵌在 kube-scheduler 内部的调度插件,称为 InTree 树内插件。
当我们自定义一个调度器时,主要工作就是编写这类可插拔的调度插件,称为 OutOfTree 树外插件,例如 https://github.com/kubernetes-sigs/scheduler-plugins 。
调度扩展
pkg/scheduler/extender.go 是调度扩展的实现,代码并不复杂。
在调度框架出现之前,调度扩展是扩展调度器的主要方式,它实际是一种 Webhook ,我们可以用任何语言编写一个 http 服务,通过配置 KubeSchedulerConfiguration ,让 kube-scheduler 在关键阶段调用我们编写的服务接口,参与调度决策。
但是调度扩展只能作用于节点过滤(Filter)、节点优先级排序(Prioritize)、抢占/驱逐Pod(Preemption)和节点绑定(Bind)这几个操作。
调度扩展是一个建议弃用的功能了,所有重点都应该转移到调度框架上。可能唯一好处就是无需重新编译 kube-scheduler 就可以扩展功能吧。
事件处理器
pkg/scheduler/eventhandlers.go 是事件处理器的实现,在里面定义了 Pod、Node、PVC 等关键资源的事件处理逻辑。在资源发生变更时,调度器通过注册的回调函数对调度队列或调度缓存进行更新,保证 Pod 状态可以及时反映到调度流程中。例如:
- 当新 Pod 创建时,添加到待调度队列;
- 当 Node 状态变更时,触发重新评估待调度 Pod 是否满足条件。
根据功能描述,可以很容易想到,事件处理器的实现使用的是 client-go 的 SharedInformerFactory。
调度流程
有了调度队列、调度缓存、调度框架、调度扩展、事件处理器这几个模块,就可以在 pkg/scheduler/schedule_one.go 串联,形成闭环。
一个成功的调度流程,可以概括为以下几个关键步骤:
- 前置阶段:事件处理器监听并接收来自 API Server 的相关事件,将待调度的 Pod 加入调度队列;调度成功的 Pod 和 Node 状态也会被更新到调度缓存中,供后续调度参考。
- 调度周期(schedulingCycle):调度器从调度队列中取出一个待调度 Pod,进入正式的调度流程。该阶段又可以细分为两个子阶段:
- 预选(Predicates)阶段:筛选出当前 Pod 可调度的候选节点,实际对应调度框架中的 PreFilter 和 Filter 扩展点,以及调度扩展的 Filter 接口。
- 优选(Prioritizing)阶段:对候选节点进行打分排序,选出最优节点,实际对应调度框架中的 PreScore 和 Score 扩展点,以及调度扩展的 Prioritize 接口。
- 绑定周期(bindingCycle):如果调度周期运行成功,即成功选出目标节点,调度器将进入绑定周期阶段。该阶段是一个异步操作,负责执行真正的绑定操作,实际对应调度框架中的 PreBind 和 Bind 扩展点,以及调度扩展的 Bind 接口。
最后总结
本文梳理了 kube-scheduler 的核心架构,重点包括:
- 调度主流程:由
schedule_one.go驱动,分为调度周期(筛选+打分)和绑定周期(绑定 Pod 到节点)。 - 调度队列与缓存:管理不同状态的 Pod,提升调度效率;
cache支持假设绑定。 - 调度框架(Framework):插件化设计,支持灵活扩展调度逻辑,是当前主流扩展方式。
- 调度扩展(Extender):基于 Webhook 的旧式扩展方式,逐步被框架取代。
- 事件处理器:监听资源变化,驱动队列和缓存更新。
微信公众号
更多内容请关注微信公众号:gopher云原生